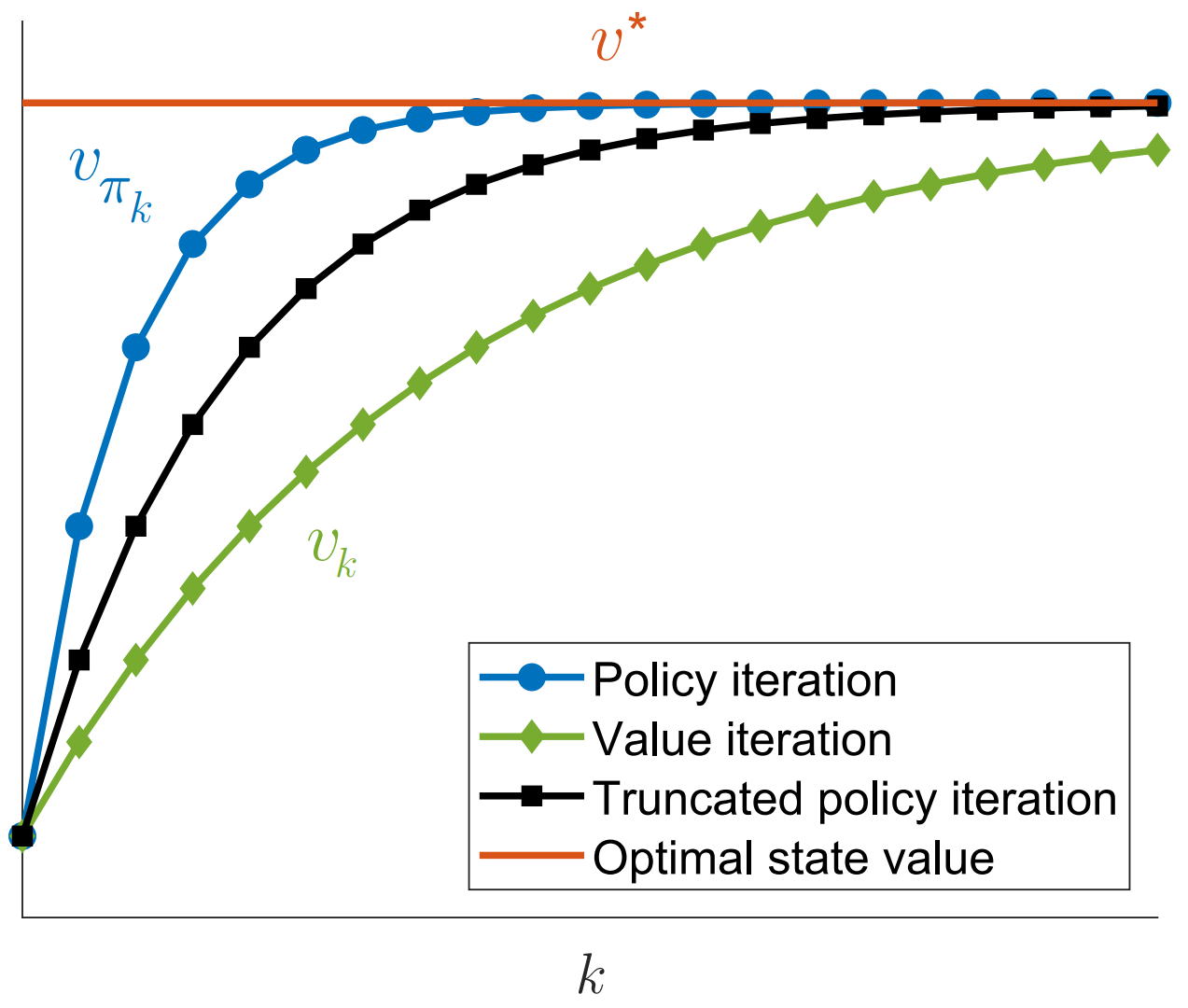
Algorithm Characteristics
- Model-Based
- Value-Based
- Non-incremental
1. Value Iteration
这个算法在 Reinforcement Learning Basics 4.3 中已经简要介绍过
Bellman Optimality Equation 的 Iterative Solution,目的是寻找 State Value
即 BOE 的 Unique Fixed Point Solution
该 Unique Fixed Point 可以用如下方式迭代解得
本部分,此算法会被用于寻找 Optimal Policy
1.1 Algorithm
Step 0 - Initialization
需要提供的内容
Probabilistic Environment Models State Value Initial Guess
Step 1 - Policy Update (PU)
solve with given
以 Elementwise Form 表达
只需要代入
,然后最大化 即可找到符合上式的 Optimal Greedy Policy Step 2 - Value Update (VU)
find next value
with 以 Elementwise Form 表达,则是代入
得 由于是 Greedy Policy,所以 Value Update 实际上只需下式即可
Policy 为唯一一个能最大化 Action Value 的
,也就是 然后代入 Elementwise Form,你会发现整件寻找 Next Value 的事情与 Policy 是什么无关
因为 Policy 本身有 Greedy 的特性,只有最大的那个 Action Value 会被留下作为
你可能会觉得 Environment Model 需要 Update,但实际上并不需要
1.2 Pseudo Code

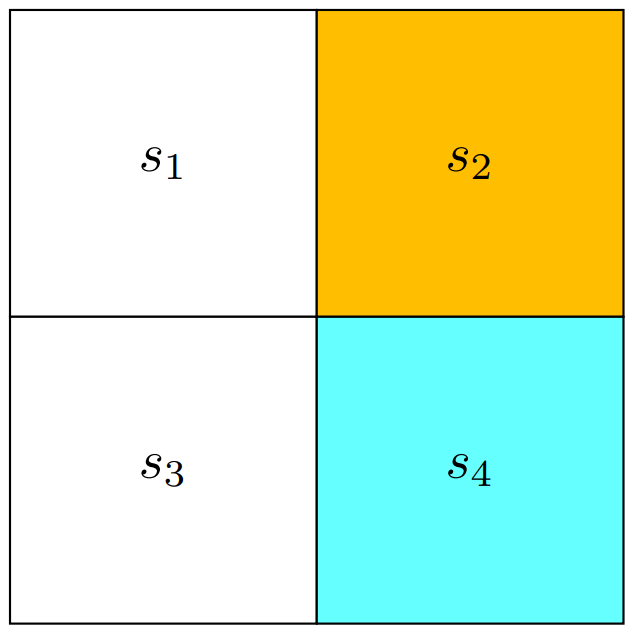
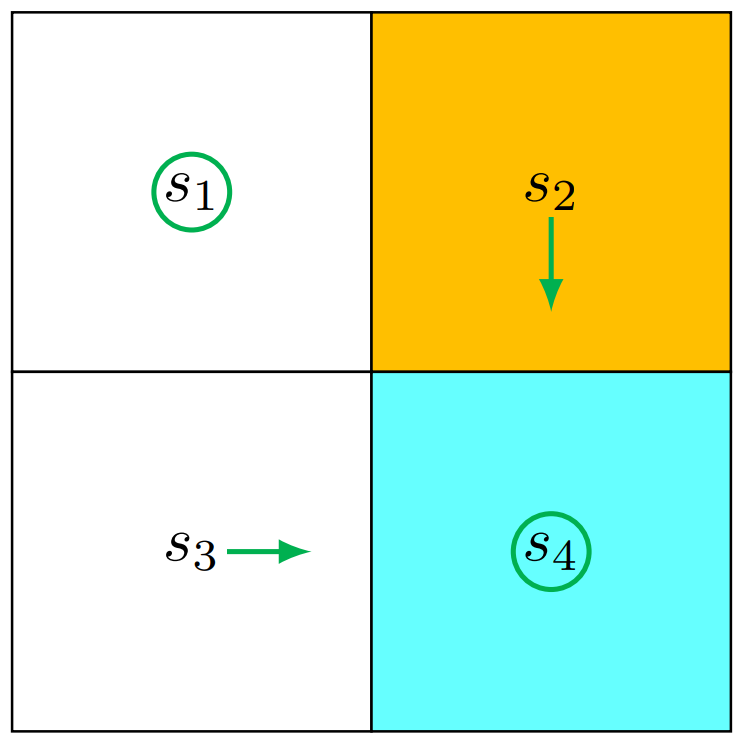
1.3 Example
在下图的场景中
黄色的
为禁区,蓝色的 为目的地 Reward 设置
Discount Rate 设置
Action Space 设置
上, 右, 下, 左, 不动
那么该场景的 Q-Table 为
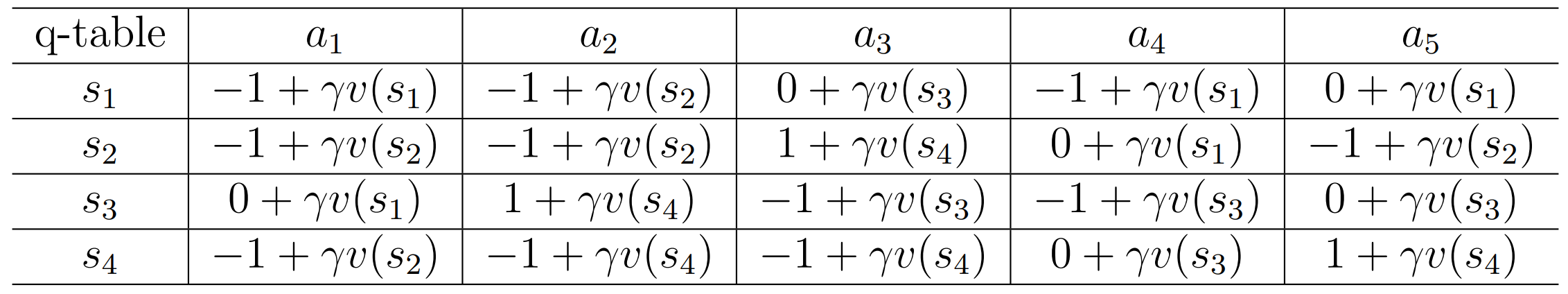
Assume the initial guess at
现在演算 Value Iteration
At
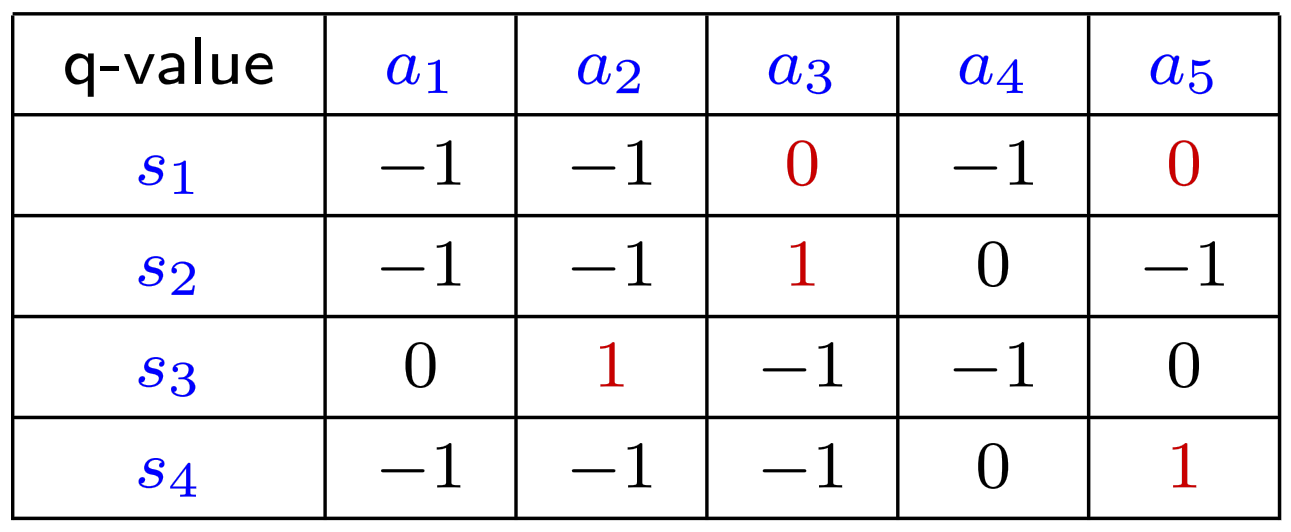
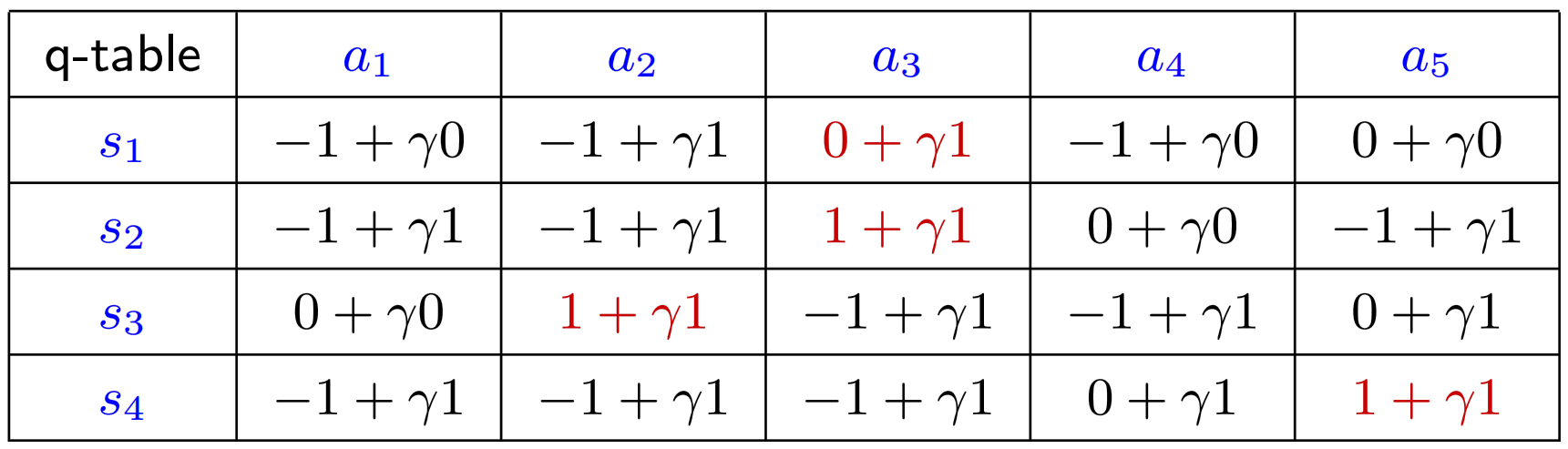
Q-Table 代入
后得到上表,标红数据为每个 State 最大的 Action Value / Q-Value Policy Update
State
有两个 Action 可以选,此处采用 Greedy Policy,所以就随便挑一个,比如 Value Update
Policy Visualized
At
Q-Table 代入
后得到上表,标红数据为每个 State 最大的 Action Value / Q-Value Policy Update
Value Update
Policy Visualized
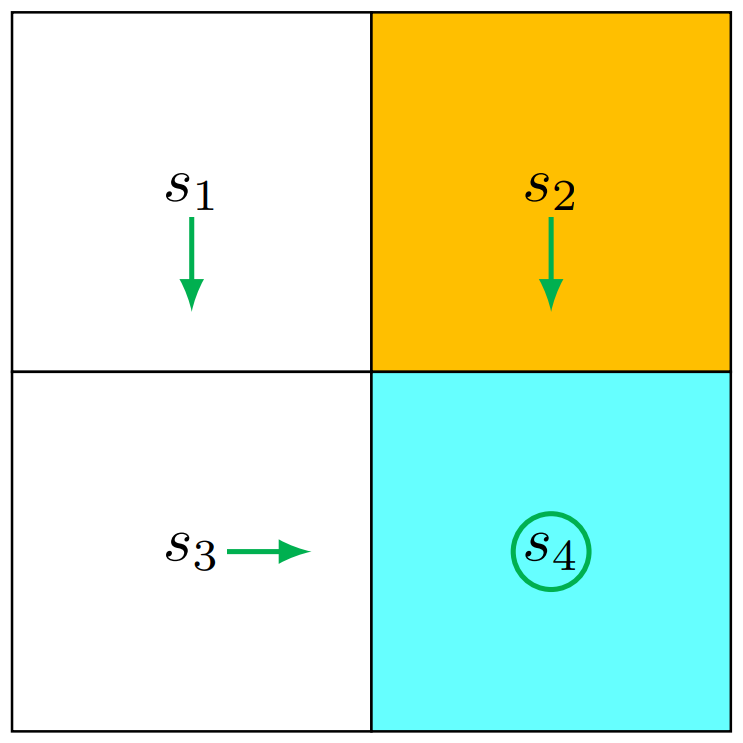
显然,迭代两次就已足以找出 Optimal Policy 了
2. Policy Iteration
这是一个只在理论中存在 的算法,可以理解为与 Value Iteration 相对的一个极端,这一点会在 3. Truncated Policy Iteration 中解释
2.1 ALgorithm
Step 0 - Initialization
需要提供的内容:Random Initial Policy
Step 1 - Policy Evaluation (PE)
Find State Value
given Policy 其实就是解个 Bellman Expectation Equation:
Closed-Form Solution
看起来很美好,但是由于需要求 Inverse Matrix,能做但是计算麻烦,直接否决
Iterative Solution
这个是合适的解法,所以 Policy Iteration 不止本身是一个迭代算法,还嵌套了另一个迭代算法
以 Elementwise Form 表达
这一步就是 Policy Iteration 只存在于理论中的原因
因为按照严格定义,你得真的算到无穷,而不是只算到收敛
Step 2 - Policy Improvement (PI)
Plug in derived
, solve for improved policy 以 Elementwise Form 表达
将求得的
代入上式即可解得 Improved Greedy Policy 为什么能断言
会比 更好?或者说,为什么能保证 ? 从定义来看有
所以可以确定
2.2 Pseudo Code

2.3 Example 1
在下图的场景中
蓝色的
为目的地 Reward 设置
Discount Rate 设置
Action Space 设置
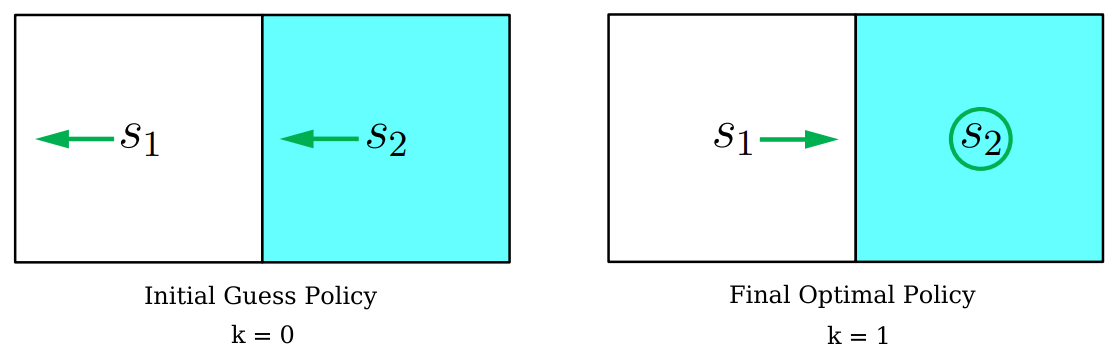
左, 不动, 右 Initial Guess 设置
为全部 ,即初始状态为左图
现在演算 Policy Iteration
At
, Policy Evaluation 方便起见,不用 Iterative Solution 直接解
At
, Policy Improvement 该场景的 Q-Table 为

代入上一步求得的
可得 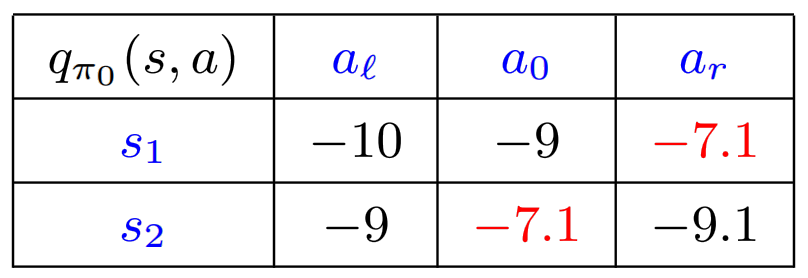
标红数据为每个 State 最大的 Action Value / Q-Value,得到的 Improved Policy 为
At
, Done 如右图中 Final Optimal Policy 所示,只用了一次迭代就达到了最优
2.4 Example 2
在下图的场景中
黄色区域为禁区,蓝色区域为目的地
Reward 设置
Discount Rate 设置
图中的 (a) ~ (h) 展示了 Policy Iteration 改进 Policy 的效果:
- 未优化
绿色 Action - 已优化
粉色 Action - 正在被优化
红色方框套绿色 Action
你会发现优化是有顺序的:离目的地越近的 State 越先被优化
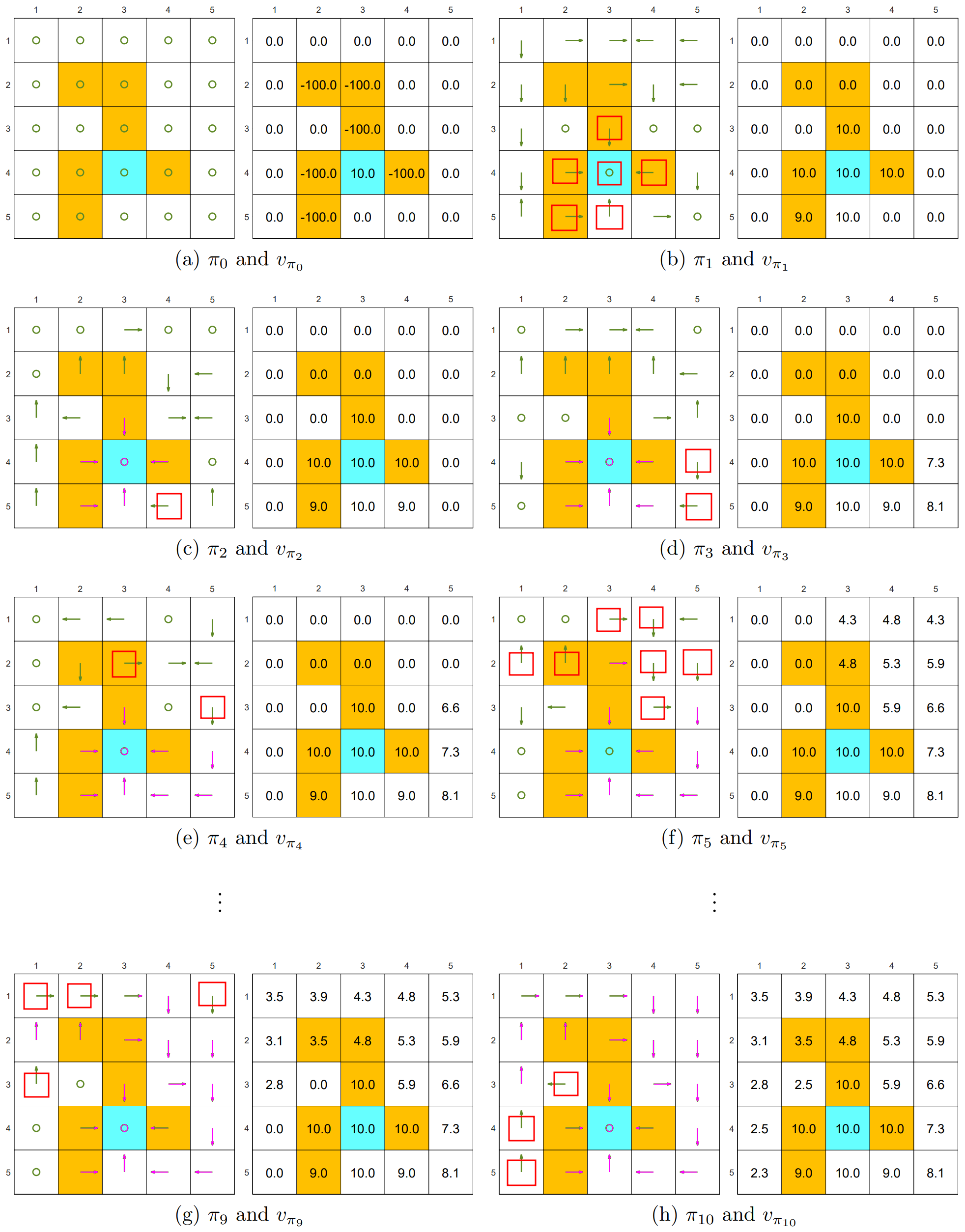
3. Truncated Policy Iteration
这是一种介于 Value Iteration 和 Policy Iteration 之间的算法,如果对比一下两种算法
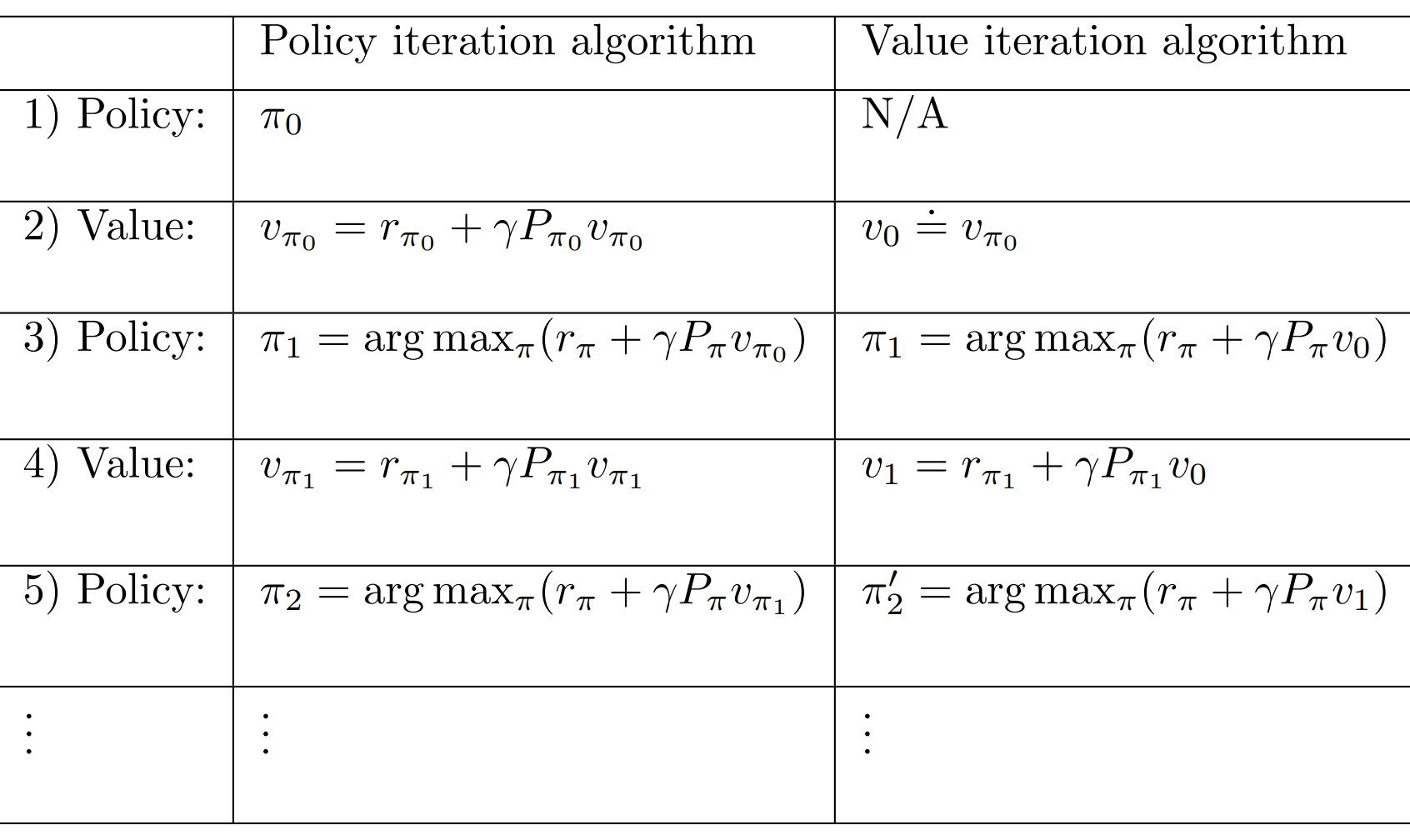
你会发现,除了 Policy Iteration 初始化了
两种算法关于 Value 的步骤 Step 4 都与 Bellman Expectation Equation 的 Iterative Solution 相关

可以看出
- Value Iteration 要求是 Iterate 一次
- Policy Iteration 要求是 Iterate 到无穷,在实操中就是迭代到收敛
- Truncated Policy Iteration 要求是 Iterate 到指定次数
所以 Truncated Policy Iteration 的步骤 / Pseudo Code 和 Policy Iteration (see 2.2) 大体是一样的
只需要改动一下套在最外面的 while 停止条件,让
[Question] Truncation 会影响收敛性吗?
不会
可证得在 BEE 的 Iterative Solution 中
因此你迭代
次 Value 会变大,迭代 次 Value 也会变大,只是收敛速度的问题