Algorithm Characteristics
- Model-Free
- Value-Based
- Non-incremental
emm,名字看起来很玄乎,但是实际上就是基于统计学的做法
1. Monte-Carlo Basics
本部分以 Value / Policy Iteration 中的 Policy Iteration 为基础介绍 Monte-Carlo Method 的基本原理
注意:后文提到的 Model-Free Policy Iteration 网上大概是搜不到的,因为压根就不值得用
1.1 Review: 大数定理
Sampling Distribution
a set of
Random Variables drawn independently & identically from a common distribution Mean of Sampling Distribution
那么依据 Law of Large Numbers,当
时,采样分布之均值将收敛于 Expectation
1.2 无模型 Policy Iteration
用 Monte-Carlo Estimation 的方式将 Policy Iteration 改成 Model Free 的版本
基本的 Policy Iteration 算法
Step 1 - Policy Evaluation (PE)
Find State Value
given Policy Step 2 - Policy Improvement (PI)
Plug in derived
, solve for improved policy
算法中与 Environment Model 强相关的部分是
为什么强相关的是
而非 ?
在算法的第一轮 Iteration 中,来自直接给定的 Initial Guess - 在第二轮及以后的 Iteration 中,
则直接来自于上一轮 Iteration 得到的
包含 Environment Model 的核心组件为 Action Value
要让 Policy Iteration 变得 Model-Free,那就得抛弃 Elementwise Form,直接通过 Mean Estimation 获取 Action Value
这种估计 Action Value 的方法,其名曰 Monte-Carlo Estimation
1.2.1 Monte-Carlo Estimation
已知
对于一组
,依据 找到所有可能的 Episode 的 Return, 是对 的采样,采样机制如下 对于 State
的每个 Action 都要采样 ,这样才能比较 Action Value 以选择 Optimal Policy 并非只采样当前 Policy 规定下,在 State
时必须或可能采取的某些 Action 到了一组
的下一个 State 时才开始完全按照 Policy 走 所以,如果
- Policy AND Environment Model All Deterministic
一组 只可能产生一个 Episode - Policy OR Environment Model Not Deterministic
一组 可能产生多个 Episode
- Policy AND Environment Model All Deterministic
假设该组
收集了 个 Return, with ,则该组 Action Value 为
"没 model 的时候得有 Data,没 Data 的时候得有 Model"
顺带一提,Data 在概率论里叫 Sample,在 RL 里叫 Experience
1.2.2 Pseudo Code
与 Policy Iteration 差别不大,不过现在只涉及 Action Value 的问题了
所以直接放弃原本 PE 中求 State Value 的内容,替换为穷举 Episode 直接估计 Action Value

因为这种算法是基于 Policy Iteration 的,所以只要 Episode 的数量够多,Convergence is guaranteed
然而这种算法效率极低,并不实用
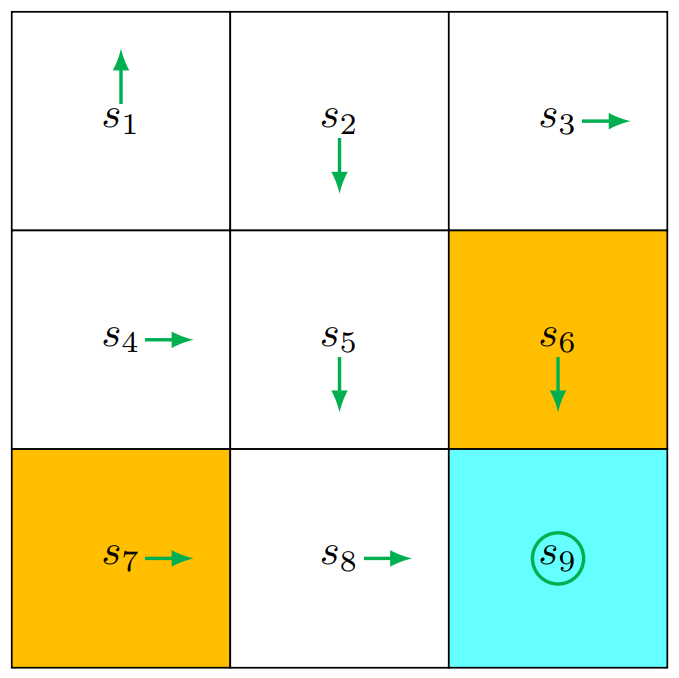
1.2.3 Example
在下图的场景中
黄色的
为禁区,蓝色的 为目的地 Reward 设置
Discount Rate 设置
Action Space 设置
上, 右, 下, 左, 不动 绿色标识为 Initial Guess Policy
Policy & Environment Models Deterministic
现在演算 Monte-Carlo Policy Iteration
At
- Policy Evaluation 一共 9 个 State,每个 State 的 Action Space 中有 5 个动作,所以一共需要计算
Episodes 此处只演示 State
的 5 个 Episode At
- Policy Improvement 肉眼观察可见最大的 Action Value 为
所以可以在 Policy
中做如下改进
2. Monte-Carlo Exploring Starts
这个是真算法了
2.1 Data Efficiency
在 1.2.2 中有言道:MCPolicyIteration 效率极低——这是在说它的 Data Efficiency 很低

一个 Episode 中有很多 Sub-Episode,复用能省略重复探索的时间,然而 MCPolicyIteration 并没有没有用,就很糟糕(
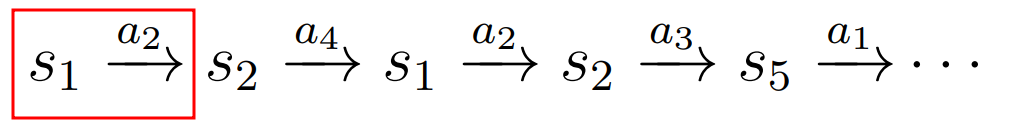
如上图红框所示,Episode 中的一个 State-Action Pair 被称为 Visit,有如下几种类型
Initial-Start Visit Method
MCPolicyIteration使用 Data 的方式每个 Episode 的检索都是完全独立的,内部的 Sub-Episode 不会被复用,非常笨拙

First Visit Method
同一个 Episode 中遇到
- 不同的 Visit,开一个 Sub-Episode 复用
- 同一个 Visit,不会被当成 Sub-Episode 复用

Every Visit Method
同一个 Episode 中只要遇到 Visit 就开一个 Sub-Episode 复用

2.2 Policy Update Efficiency
一共就两种方式
Method 1
收集从一个 State-Action Pair 出发的所有 Episode 的 Return,得到 Expectation,然后估计 Action Value
Method 2
用单一一个 Episode 的 Return 直接估计 Action Value,improve policy episode-by-episode
有点 Stochastic Gradient Descent 的感觉,不精确,很狂野,但实际效果不错
2.3 Pseudo Code
算法名称叫 Monte-Carlo Exploring Start (Every Visit Method 版)
Exploring Start 的意思是,确保每对
因为当前的方法无法确保每对
即,无法 guarantee 一定有机会被复用

这个算法印证了为什么说 “动态规划是从后往前规划的“
3. Monte-Carlo
如果你嫌 Monte-Carlo Exploring Starts 的 "Exploring Starts" 条件麻烦
那就可以用这个基于 Soft Policy 的算法,让 Policy 从 Deterministic 变得 Stochastic
- Soft Policy = Probability to take any Action is Positive
本算法使用的 Soft Policy 叫
3.1
where
Number of Actions for
特性如下
Greedy Action 的概率
Other Actions 的概率 可以调节 "Exploration" 与 "Exploitation" 的平衡
完全 Exploitation
此时是纯 Exploitation,和一般的 Greedy Policy 没有区别
看起来比较 “短视”
完全 Exploration
此时 Greedy Action 与 Other Actions 概率相等,显然更加 "Exploration"
看起来比较 “远视”,但不如说是完全不带判断的 “盲视”
二者的平衡
Epsilon Annealing
一开始取较大的数值 Start High (
),然后衰减到较小的数值 End Low ( ) A common practice to balance exploitation & exploration
与纯粹的 Greedy Policy 相比,
但缺点是牺牲了 Optimality,且是 explore blindly
(see 3.3.1, 3.3.2)
3.2 Pseudo Code
well,只需要把 2.3 的 Exploring Start 的 Pseudo Code 中 Policy Improvement 的部分改下即可

哦
(真的有人会忘记这种事吗?蠢爆了好吧,但我觉得还是提醒一下吧)
3.3 Examples & Properties
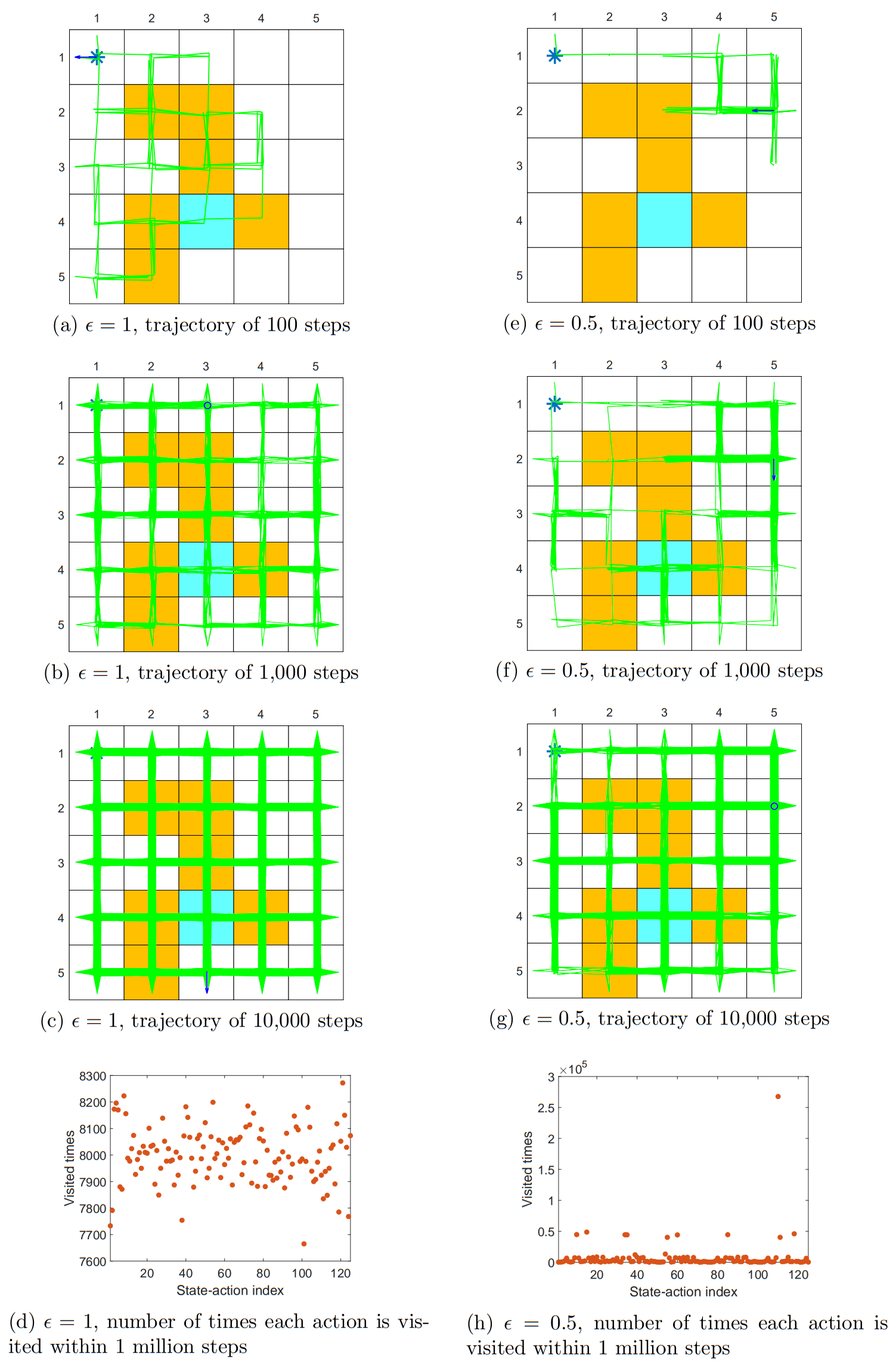
3.3.1 Exploration & Exploitation
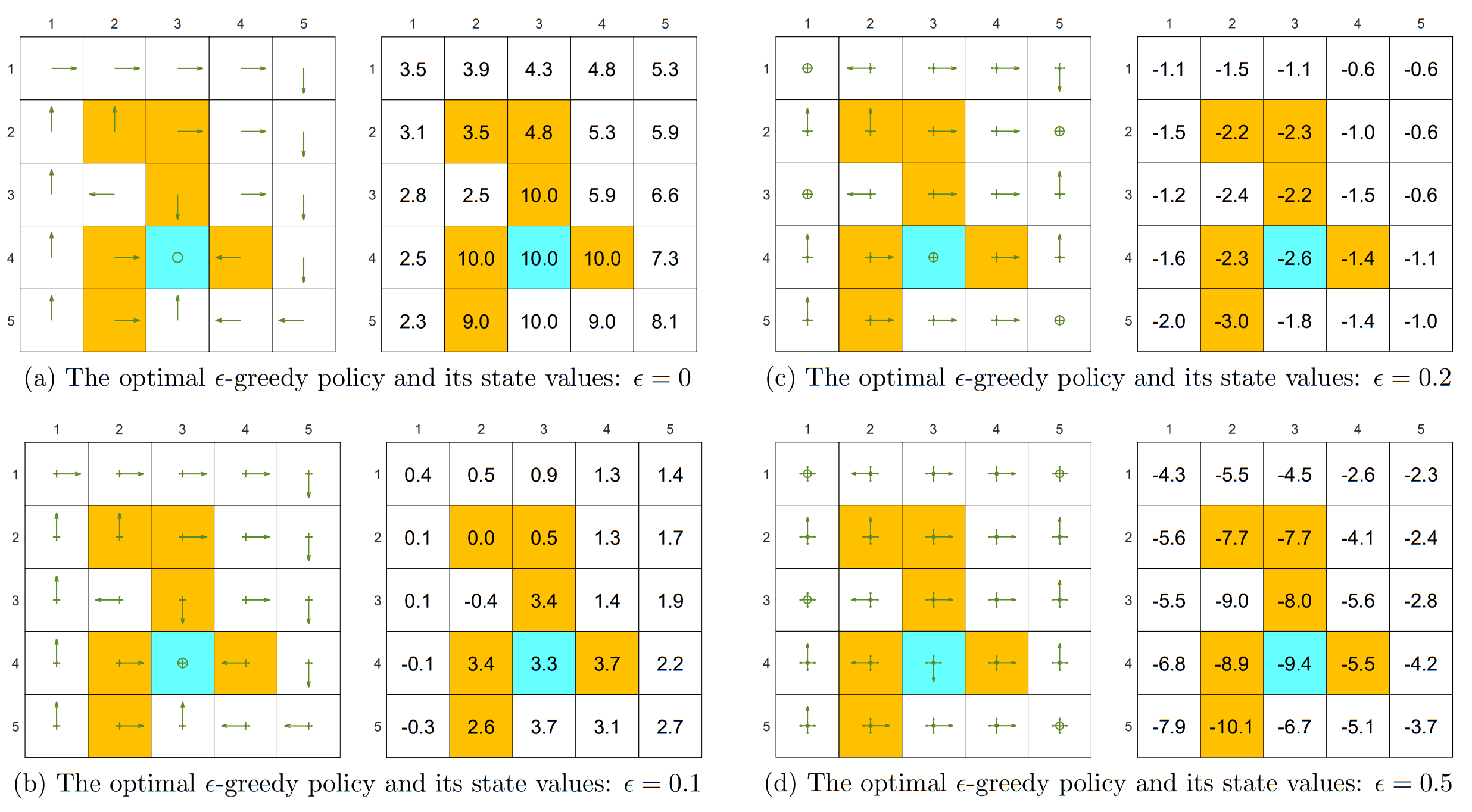
3.3.2 Optimality
给定一个固定的 Policy,代入不同取值的
虽然所有其他 Policy 都能与 Greedy 状态下(
但是 State Value 的变化说明,更大的
当
的时候,Target 的 State Value 已经是负数了 原因在于 Target 附近全是 Forbidden Area,而探索性的提升会让处于 Target 位置的 Agent 有更高的概率踩到 Forbidden Area
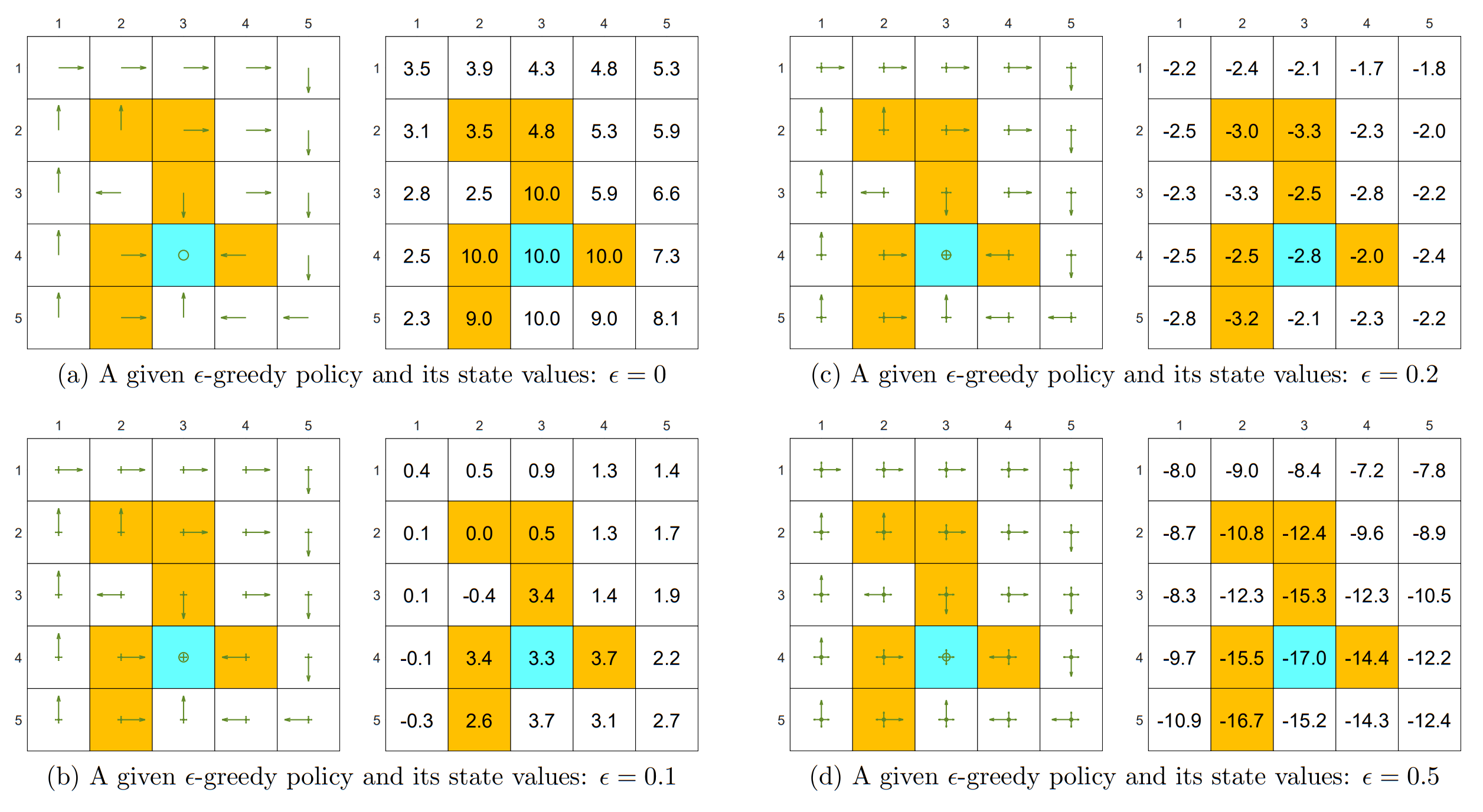
3.3.3 Consistency
在不同